How does ML work?
Each flavor of ML and each individual model works in very different ways, exploiting different parts of mathematics and data science. However, in general, ML works by taking in data, finding relationships within the data, and giving as output what the model learned, as illustrated in Figure 10.2.
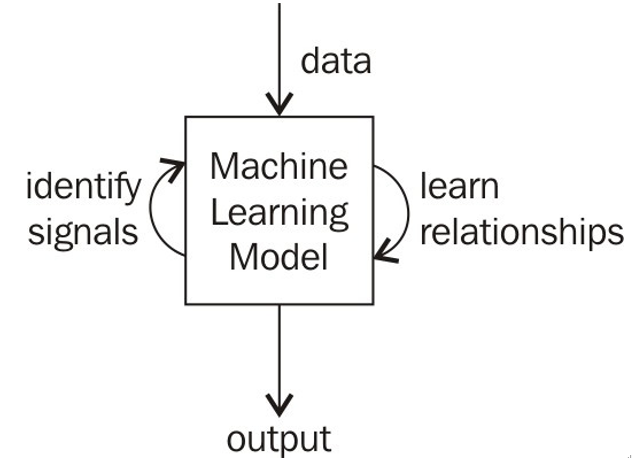
Figure 10.2 – An overview of ML models taking in input data, learning signals, and identifying patterns in order to produce a meaningful and interpretable output
As we explore different types of ML models, we will see how they manipulate data differently and come up with different outputs for different applications.
Types of ML
There are many ways to segment ML and dive deeper. In Chapter 1, Data Science Terminology, I mentioned statistical and probabilistic models. These models utilize statistics and probability, which we’ve seen in the previous chapters, in order to find relationships between data and make predictions. In this chapter, we will implement both types of models. In the following chapter, we will see ML outside the rigid mathematical world of statistics/probability. You can segment ML models by different characteristics, including the following:
- The types of data organic structures they utilize (tree, graph, or neural network (NN))
- The field of mathematics they are most related to (statistical or probabilistic)
- The level of computation required to train (deep learning (DL))
Branching off from the top level of ML, there are the following three subsets:
- Supervised learning (SL)
- Unsupervised learning (UL)
- Reinforcement learning (RL)
Let’s go into each one of these one by one. Our next chapter will include multiple examples of the first two, with the third one being slightly out of the scope of our introductory book. You can always find more resources in our code base!
SL
Simply put, SL finds associations between features of a dataset (independent variables) and a target (dependent) variable. For example, SL models might try to find the association between a person’s health features (heart rate, weight, and so on) and that person’s risk of having a heart attack (the target variable). These associations allow supervised models to make predictions based on past examples. Supervised ML (SML) models are often called predictive analytics models, named for their ability to predict the future based on the past. This is often the first thing that comes to people’s minds when they hear the term ML, but it in no way encompasses the realm of ML.
SML requires a certain type of data called labeled data – data that acts as full, correct, and complete examples of the features and target variable. Figure 10.1 shows a snippet of labeled data. The goal is to let our model learn by giving it historical examples that are labeled with the correct answer.
Recall the facial recognition example. That is an SL model because we are training our model with the previous pictures labeled as either face or not face, and then asking the model to predict whether or not a new picture has a face in it.
First, let us separate the data into two distinct parts, as follows:
- The features, which are the columns that will be used to make our prediction. These are sometimes called predictors, input values, variables, and independent variables.
- The response, which is the column that we wish to predict. This is sometimes called outcome, label, target, and dependent variable.
SL attempts to find a relationship between features and responses in order to make a prediction. The idea is that, in the future, a data observation will present itself, and we will only know the predictors. The model will then have to use the features to make an accurate prediction of the response value. Figure 10.3 shows a visualization of how we generally use supervised models: we train (fit) them using labeled training data and use the result to predict unseen cases (features without the response) to make final predictions:
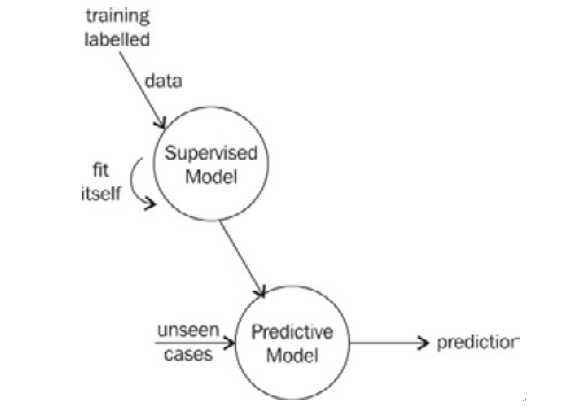
Figure 10.3 – Supervised models are fit using labeled training data and are then used to make predictions from unseen cases